Evaluation
Summary of Achievements
The overall evaluation of this project is positive. We were able to meet all of the key requirements of our application. Following we can see a run down of the MoSCoW Requirements and their final status.
MoSCoW Requirements
| ID | PRIORITY | DESCRIPTION | TYPE | STATUS | CONTRIBUTORS |
|---|---|---|---|---|---|
| M1 | MUST | System must recognize letters and writing styles | Functional | Completed | Andrei, Kamil |
| M2 | MUST | System must allow to search similar letters based on a selection of a character. | Functional | Completed | Andrei, Francesco, Kamil |
| M3 | MUST | System must be a web-based application. | Functional | Completed | Francesco, Kamil |
| M4 | MUST | System must let the user select a letter through a manual selection tool. | Functional | Completed | Francesco |
| S1 | SHOULD | System should find characters that with different scale | Functional | Completed | Kamil |
| S2 | SHOULD | System should be able to account for false negatives. | Functional | Completed | Kamil |
| S3 | SHOULD | System should allow user to import images to the his personal Manuscript Collection. | Functional | Completed | Francesco |
| S4 | SHOULD | System should allow user to view the imported images in the Manuscript Collection. | Functional | Completed | Francesco |
| S4 | SHOULD | System should have a memorable UI | Non-functional | Completed | Andrei, Francesco |
| S5 | SHOULD | System should have consistent navigation system in each page. | Non-functional | Completed | Francesco |
| C1 | COULD | System could allow each user to have a personal training data settings. | Functional | Not Completed | Andrei, Kamil |
| W1 | WOULD | System would make use of Deep Neural Networks to improve efficiency | Functional | Not Completed | Andrei, Kamil |
Individual Contribution table
| Task | Andrei | Francesco | Kamil |
|---|---|---|---|
| Client Liaison | 10% | 70% | 20% |
| Academic Liaison | 40% | 40% | 20% |
| Research | 40% | 20% | 40% |
| Deployment | 35% | 40% | 25% |
| Frontend Programming | 5% | 85% | 10% |
| Backend Programming | 20% | 30% | 50% |
| Showcase Website | 75% | 10% | 15% |
| Poster | 80% | 10% | 10% |
| Videos | 10% | 80% | 10% |
| Reports | 50% | 30% | 20% |
| Testing | 20% | 40% | 40% |
| Overall | 30% | 36% | 34% |
Known bugs
The final version of the application present some two graphical related bugs.
| Bug ID | Bug Description | Priority |
|---|---|---|
| B1 | When accessing the cropping tool on tablet devices there is no way of zooming in to crop more accurately | Medium |
| B2 | When browsing a manuscript, vertical scroll on the background page is enabled | Low |
The bugs presents are mostly related to graphics and interface. To solve B1 it will be necessary to modify our cropping tool component to accommodate for a zoom button interface. Regarding B2, changing the modal view to a new page will fix the graphical problem.
Critical Evaluation of Scribal Handwriting
User Interface
The user interface results being intuitive and clean to most users, as shown by our user testing phase. Furthermore, it is aligned with the British Library color palette maintaining consistency with their color space and styling conventions. The development of the user interface was a user-centred design, always keeping in mind the end user, his needs and technical level. The result offers a intuitive and memorable navigation experience.
Functionality
Regarding the main functionalities, the main key components of requested system were completed. The main problem to tackle was to create an algorithm that would recognize similar characters in different documents. Furthermore, solve problems such as miss-matches between characters, long computation time and overall complexity was our goal. After several attempts, our final normalized cross correlation algorithm offers a balanced mix between performance and accuracy, computing 3 to 4 pages with a small to medium image to find (25x25 pixel), in under 2 minutes. Moreover, our Manuscript Collection feature, that allows for upload and retrieval of user uploaded document, works reliably.
Stability
When testing our application, no major stability issue has emerged. The login, registration and user account presented no issues, as well as image upload and download from the online database. Regarding the connection with our back-end server for computation, we made sure to conduct checking on the information sent and received to avoid possible errors when running the algorithm. Therefore, all option values in the front-end side were locked to the accepted range of the algorithm, and on the server side another final check was conducted. Although the system is design to allow multiple connections and requests from the web-app, our major concern was a functional prototype rather than a final production-ready product.
Efficiency
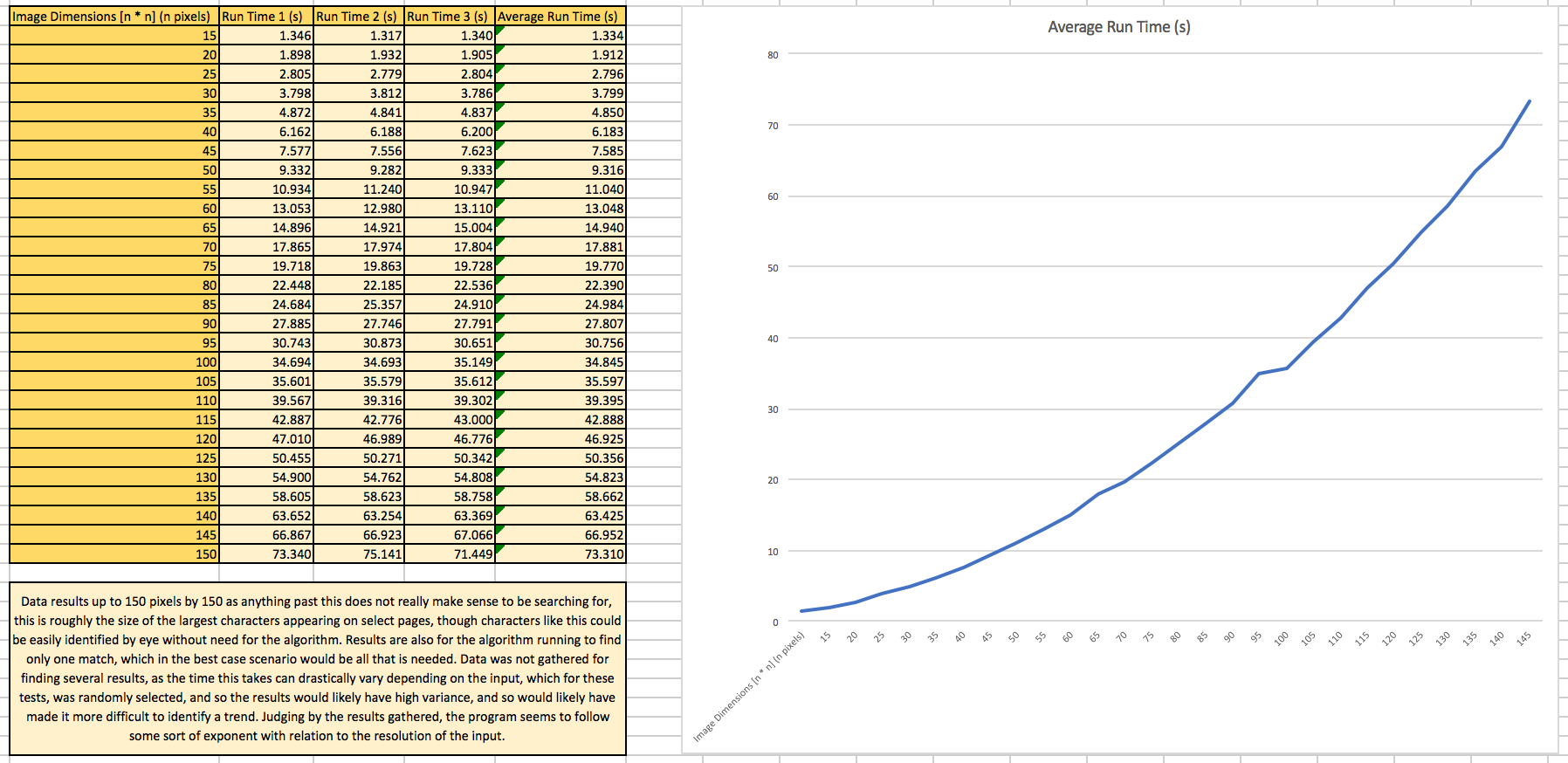
Our application runtime depends largely on normalized cross correlation (NCC). Due to the nature of this process, it must be applied each time that either the search image or the search field changes. In our implementation, we manage to save some time running NCC too often by saving the array that it creates and breaking it down to retrieve more detail about each result for every search. From the tests that we have performed, it is clear that the runtime of NCC with respect to the pixel size of the input image, has a trend following some sort of exponent. The two variables that affect the runtime are the number of pages to scan through and the number of resizes to perform on the input. For a selection of n pages, the runtime is simply multiplied by a factor of n. The runtime for any resize is more complicated, however, as with each resize, the size of the input decreases, and so the application will run faster, for this reason, the runtime of the application with respect to the number of resizes follows a ln(x) trend when graphed.
Compatibility
Building our Web-App with the React.js Framework we were able to ensure compatibility with all major internet browsers. A complete list can be found in this table:
| Browser | Compatible Version |
|---|---|
| Microsoft IE | > 9 |
| Microsoft Edge | > 40.15063 |
| Google Chrome | > 61.0.3163 |
| Firefox | > 52 |
| Safari | > 8 |
Maintainability
A major goal when we started the design phase of the project was separation of the components for reusability and maintainability. For this reason, the choice of using React.js as our front end framework allowed us to create individual components such as cropping tools, image uploaders and viewers that were later plugged in the specific page offering an easier replacement of parts in future development. Moreover, by delegating the computation of the results to a separated back-end component we allowed for easy interchangeability of future implementations. Finally, in order to aid possible future changes on our implementation, insightful comments were spread in the codebase.
Project Management
Our final critical evaluation of the project management is overall positive. We delivered the application on time with all team members contributing to the project in different sections. The team met regularly, providing progress update, problems encountered and future plans. Furthermore, a share Google Drive folder was used to create and maintain all the documents and reports created during the project. This allowed team members to work concurrently and review each other's work very effectively. Regarding client meetings and updates, we report each major update in bi-weekly reports and communication with clients. A team project contribution spreadsheet was also created to keep track of all of our team’s contribution for each week of work/development. This enabled us to keep track of our project in a consistent way. Regarding source code, we created a GitHub private repository to allow for version control fast code sharing and ease of contribution along all team members.
Future work
The final application was overall successful, the client was satisfied with it and the main requirements were met. At the end of the delivering phase, as a team, we run an evaluation of possible future improvements and additions to our system. We divided the improvements into three categories: front-end, back-end and Hosting solutions.
Front-End future work
Regarding the front end solution the main points to be addressed are: - Simplification of some components to increase interchangeability; - Support for small screen mobile devices, allowing for a fully portable solution; - Introduction of a new Manuscript Viewer tool allowing user to markup uploaded documents.
Back-End future work
Our backend image-processing algorithm offers a balance between performance and computation time need to perform a search. To increase the speed of it a machine learning implementation of the algorithm, that uses a tweaked model of the VGG-16 neural network instead of the Normalized Cross-Correlation could be used for better performance and features. This would allow, for example, to recognize the language of a paragraph, retaining information on the definition of "relevant resemblance" as defined by the user, and predict information about a manuscript such as authors, location of production and historic period. In addition, the manuscripts already uploaded in the database could be pre-processed to reduce the computing a search on a large selection of documents. This would greatly improve the time efficiency.
Hosting Solution future work
The current version of the application is not completely deployed online for production. To allow our application to be used as a reliable tool by our client, a solid hosting solution need to be used. Furthermore, this solution will need to take into account possible deep neural network implementations of the algorithm, allowing to perform the calculation using GPU power instead of CPU.